
This post was co-written with Luke Sudgen, Lead DevOps Engineer Post Trade, and Padraig Murphy, Solutions Architect Post Trade, from London Stock Exchange Group.
In this post, we’ll discuss some failure scenarios that were tested by London Stock Exchange Group (LSEG) Post Trade Technology teams during a chaos engineering event supported by AWS. Chaos engineering allows LSEG to simulate real-world failures in their cloud systems as part of controlled experiments. This methodology improves resilience and observability, which reduces risk and helps achieve compliance with regulators before deploying to production.
Introduction, tooling, and methodology
As a heavily regulated provider of global financial markets infrastructure, LSEG is always looking for opportunities to enhance workload resilience. LSEG and AWS teamed up to organize and run a 3-day AWS Experience-Based Acceleration (EBA) event to perform chaos engineering experiments against key workloads. The event was sponsored and led by the architecture function and included cross-functional Post Trade technical teams across various workstreams. The experiments were run using AWS Fault Injection Service (FIS) following the experiment methodology described in the Verify the resilience of your workloads using Chaos Engineering blog post.
Resilience of modern distributed cloud systems can be continuously improved through reviewing workload architectures and recovery, assessing standard operating procedures (SOPs), and building SOP alerts and recovery automations. AWS Resilience Hub provides a comprehensive tooling suite to get started on these activities.
Another key activity to validate and enhance your resilience posture is chaos engineering, a methodology that induces controlled chaos into customer systems through real-world controlled experiments. Chaos engineering helps customers create real-world failure conditions that can uncover hidden bugs, monitor blind spots, and manage bottlenecks that are difficult to find in distributed systems. This makes it a very useful tool in regulated industries such as financial services.
Architectural overview
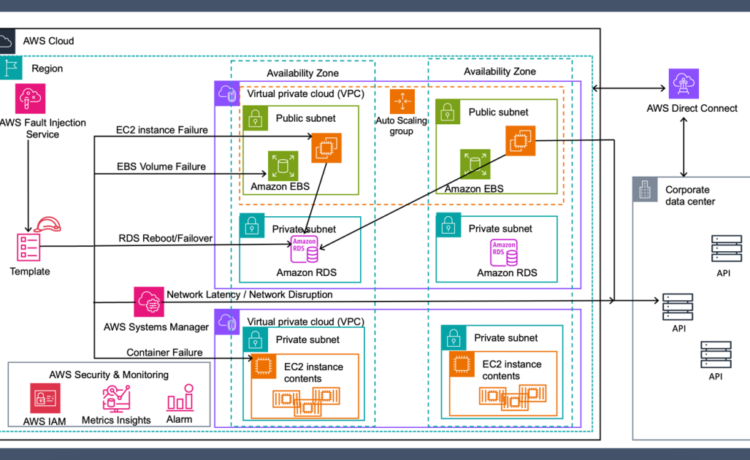
The architectural diagram in Figure 1 comprises a three-tier application deployed in virtual private clouds (VPCs) with a multi-AZ setup.
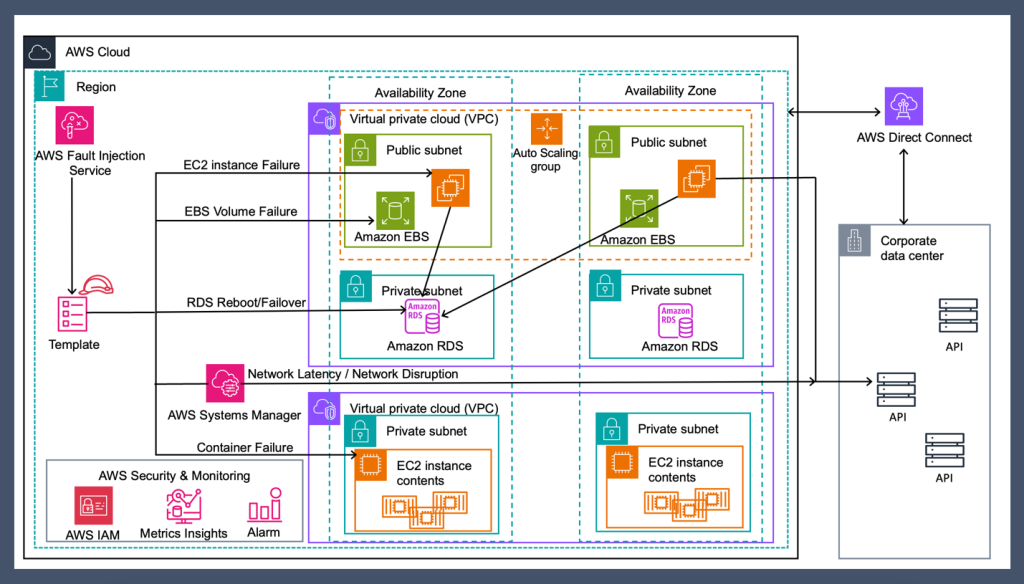
Figure 1. Chaos engineering pattern for hybrid architecture (3-tier application)
Operating within a public subnet, the web application creates a hybrid architecture by using an Amazon Elastic Compute Cloud (Amazon EC2) Auto Scaling group and connecting to an Amazon Relational Database Service (Amazon RDS) database that’s located in a private subnet and connected with on-premises services. Additionally, a number of internal services are hosted in a separate VPC, housed within containers. FIS provides a controlled environment to validate the robustness of the architecture against various failure scenarios, such as:
- Amazon EC2 instance failure that causes the application or container pod on the machine to also fail
- Amazon RDS database instance reboot or failover
- Severe network latency degradation
- Network connectivity disruption
- Amazon Elastic Block Store (Amazon EBS) volume failure (IOPS pause, disk full)
Amazon EC2 instance and container failure
The objective of this use case is to evaluate the resilience of the application or container pod running on Amazon EC2 instances and identify how the system can adapt itself and continue functioning during unexpected disruptions or instability of an instance. You can use aws:ec2:stop-instances or aws:ec2:terminate-instances FIS actions to mimic different EC2 instance failure modes. The response of running containers to the different instance failures was also assessed. If you’re running containers within a managed AWS service such as Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS), you can use FIS failure scenarios for ECS tasks and EKS pods.
Amazon RDS failure
RDS failure is another common scenario you can use to identify and troubleshoot database managed service failures from failovers and node reboots at a large scale. FIS can be used to inject reboot/failover failure conditions into the managed RDS instances to understand the bottlenecks and issues from disaster failovers, sync failures, and other database-related problems.
Severe network latency degradation
Network latency degradation injects latency in the network interface that connects two systems. This helps you understand how these systems handle a data transfer delay and your operational response readiness (alerts, metrics, and correction). This FIS action (aws:ssm:send-command/AWSFIS-Run-Network-Latency) uses the Linux traffic control (tc) utility.
Network connectivity disruption
Connectivity issues like traffic disruption or other network issues can be simulated with FIS network actions. FIS supports the aws:network:disrupt-connectivity action to test your application’s resilience in the event of total or partial connectivity loss within its subnet, as well as disruption (including cross-Region) with other AWS networking components such as route tables or AWS Transit Gateway.
Amazon EBS volume failure (IOPS pause)
Disk failure is a problematic issue in real-time operations-based systems. It can lead to transactions failing due to I/O failures or storage failure during peak activity in heavy workloads. The EBS volume failure actions test system performance under different disk failure scenarios. FIS supports the aws:ebs:pause-volume-io action to pause I/O operations on target EBS volumes, as well as other failure modes. The target volumes must be in the same Availability Zone and must be attached to instances built on the AWS Nitro System.
Outcomes and conclusion
Following the experiment, the teams from LSEG successfully identified a series of architectural improvements to reduce application recovery time and enhance metric granularity and alerting. As a second tangible output, the teams now have a reusable chaos engineering methodology and toolset. Running regular in-person cross-functional events is a great way to implement a chaos engineering practice in your organization.
You can start your resilience journey on AWS today with AWS Resilience Hub.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}